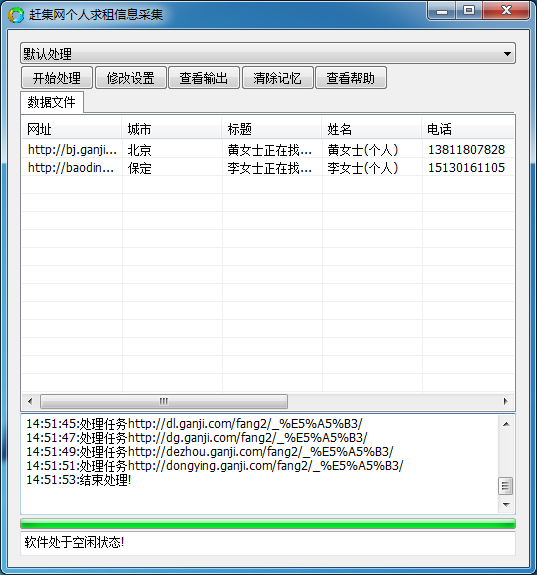
简介
功能
演示
使用
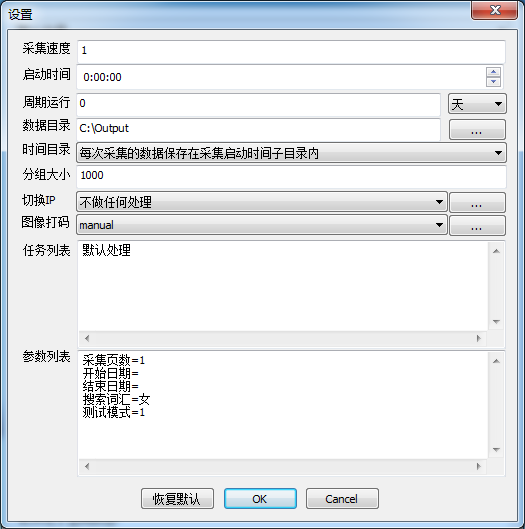 采集页数:
赶集最新更新的数据总是在最前面,
如果您每次只是需求最新更新的数据,就可以把这个设置为1或者2。
如果您要采集所有展示出来的页面,就设置为0.
采集页数:
赶集最新更新的数据总是在最前面,
如果您每次只是需求最新更新的数据,就可以把这个设置为1或者2。
如果您要采集所有展示出来的页面,就设置为0.
开始日期和结束日期:
指定了采集某个时间范围内的内容。
如果开始日期和结束日期留空,就表示最近三天的内容。
如果开始日期和结束日期不为空,则表示获取指定的日期区间的内容。
日期的格式是YYYY-MM-DD,例如2017-05-18
搜索词汇
搜索词汇可以多个,每个搜索词汇之间用逗号隔开。
测试模式
测试模式为1的时候,只处理了三个省份的前三个城市,也就是9个城市的数据。
测试模式仅仅是为了方便客户快速验证问题而留的。
当客户正常使用采集器的时候,请将测试模式设置为0.
备注
赶集网采集的时候,必须不断换IP采集。
采集时要换ip采集,需要一个秒换ip的vps服务器
VPS上软件设置操作请参考怎么设置软件自动换IP
软件是二级过滤体系。
软件里先对采集页数做了过滤,
然后在对指定的采集页数里面采集的条目在做时间的过滤。
这个日期的范围应该是采集页数对于的内容里的时间范围,指定一个网站上不显示的内容的时间范围,或者指定一个采集页数内容外面的时间范围都是无意义的。