“为什么开始采集后过一段时间才可以看到数据”的版本间的差异
来自JsRobot
| 第12行: | 第12行: | ||
[[image:20160119_GuanDuBianLi.gif]] | [[image:20160119_GuanDuBianLi.gif]] | ||
[[image:20160119_ShengDuBianLi.gif]] | [[image:20160119_ShengDuBianLi.gif]] | ||
| + | 深度遍历的方法, | ||
| + | 优点是客户可以很快的看到数据。 | ||
| + | 缺陷是,可能会导致COOKIE失效。 | ||
| + | 广度遍历的方法, | ||
| + | 缺陷是,客户要在枝干遍历完成后才能看到数据。 | ||
| + | 优点是,可以在COOKIE使失效前就完成树干的遍历。 | ||
| + | 我们的项目采集用的是广度遍历的处理方法,所以在采集开始后,要过一段时间才能看到数据。 | ||
2016年1月19日 (二) 14:08的版本
我们可以把数据采集的过程想象为一个猴子在树上摘苹果的过程。
猴子的起点是地面。
猴子的处理过程如下:
1 从地面爬到树干上面,
2 从树干爬到枝干上面,
2 从枝干爬到树枝上面,
3 然后在树枝上摘下苹果。
这时候就有两种处理逻辑
深度遍历:从某个顶点出发,首先访问这个顶点,然后找出刚访问这个结点的第一个未被访问的邻结点,然后再以此邻结点为顶点,继续找它的下一个新的顶点进行访问,重复此步骤,直到所有结点都被访问完为止。
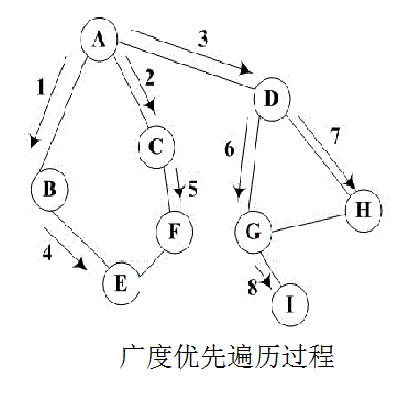
广度遍历:从某个顶点出发,首先访问这个顶点,然后找出这个结点的所有未被访问的邻接点,访问完后再访问这些结点中第一个邻接点的所有结点,重复此方法,直到所有结点都被访问完为止。
可以看到两种方法最大的区别在于前者从顶点的第一个邻接点一直访问下去再访问顶点的第二个邻接点;后者从顶点开始访问该顶点的所有邻接点再依次向下,一层一层的访问。
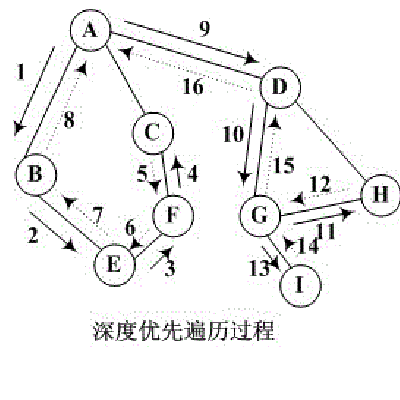 深度遍历的方法,
优点是客户可以很快的看到数据。
缺陷是,可能会导致COOKIE失效。
广度遍历的方法,
缺陷是,客户要在枝干遍历完成后才能看到数据。
优点是,可以在COOKIE使失效前就完成树干的遍历。
我们的项目采集用的是广度遍历的处理方法,所以在采集开始后,要过一段时间才能看到数据。
深度遍历的方法,
优点是客户可以很快的看到数据。
缺陷是,可能会导致COOKIE失效。
广度遍历的方法,
缺陷是,客户要在枝干遍历完成后才能看到数据。
优点是,可以在COOKIE使失效前就完成树干的遍历。
我们的项目采集用的是广度遍历的处理方法,所以在采集开始后,要过一段时间才能看到数据。

