“苏州工商新公司检索工具”的版本间的差异
来自JsRobot
(→简介) |
(→设置) |
||
| (未显示同一用户的10个中间版本) | |||
| 第2行: | 第2行: | ||
这是一个提取江苏工商新公司名称的工具。 | 这是一个提取江苏工商新公司名称的工具。 | ||
==功能== | ==功能== | ||
| − | + | 指定一个起始编号,依次检查后续编号的有效性。 | |
获取有效编号对应的公司名称。 | 获取有效编号对应的公司名称。 | ||
需要支持多个帐号轮换登陆。 | 需要支持多个帐号轮换登陆。 | ||
需要识别图像验证码。 | 需要识别图像验证码。 | ||
| + | 需要支持多个初始编号。 | ||
| + | 需要处理验证码识别失败的情况 | ||
| + | 需要处理登陆状态过期的情况 | ||
| + | 需要处理帐号禁用的情况。 | ||
==使用== | ==使用== | ||
| + | 先安装软件 | ||
| + | 然后用您的用户和密码登陆软件, | ||
| + | 然后把我们发给您的"辅助配置"压缩包里的文件解压到c:\output, | ||
| + | 然后修改用户列表文件里的用户和帐号, | ||
| + | 然后修改初始编号中的初始编号, | ||
| + | 然后点击开始提取就可以了。 | ||
| + | |||
==设置== | ==设置== | ||
| − | + | 工作目录=c:\output | |
| − | + | ||
| − | + | ||
| − | + | ||
探测步长=20 | 探测步长=20 | ||
测试模式=0 | 测试模式=0 | ||
| − | 用户清单 | + | |
| − | + | 工作目录 | |
| + | 工作目录指定了软件的工作目录, | ||
| + | 软件会从这个工作目录中读取相应的配置文件。 | ||
| + | 软件也会把输出结果写到这个工作目录。 | ||
| + | |||
| + | |||
| + | 工作目录中的文件组织结构如下 | ||
| + | 过滤词汇.txt | ||
| + | 图像识别.lib | ||
| + | 图像识别.txt | ||
| + | 子配置目录(例如0000 0001 0002) | ||
| + | [[image:SuZhouGongShangXinGongSiJianSuoGongJu_Setting.png]] | ||
| + | |||
| + | |||
| + | 子配置目录中的关键文件如下 | ||
| + | 初始编号.txt | ||
| + | 用户清单.txt | ||
| + | [[image:SuZhouGongShangXinGongSiJianSuoGongJu_Setting_Sub.png]] | ||
| + | |||
| + | |||
| + | 用户清单.txt | ||
这是一个纯文本文件, | 这是一个纯文本文件, | ||
每行是一个用户信息, | 每行是一个用户信息, | ||
一行内容的前面是用户名,后面是密码,中间是英文的逗号。 | 一行内容的前面是用户名,后面是密码,中间是英文的逗号。 | ||
| − | 初始编号 | + | 初始编号.txt |
这也是一个文本文件。 | 这也是一个文本文件。 | ||
文件里面就是初始编号。 | 文件里面就是初始编号。 | ||
| 第28行: | 第56行: | ||
在退出的时候,会把最后有效编号的下一个编号保存在这个文件里。 | 在退出的时候,会把最后有效编号的下一个编号保存在这个文件里。 | ||
这样确保用户之需要设置一次,就可以反复运行。 | 这样确保用户之需要设置一次,就可以反复运行。 | ||
| + | |||
| − | + | 图像识别.lib | |
帐号登录的时候,有验证码。 | 帐号登录的时候,有验证码。 | ||
这个模块是验证码识别库。 | 这个模块是验证码识别库。 | ||
| 第36行: | 第65行: | ||
长期而言是非常合算的。 | 长期而言是非常合算的。 | ||
| − | + | ||
| − | + | 图像识别.txt | |
| + | 这个文件包含了图像识别库的密码。 | ||
这个是为了避免别人直接使用你的识别库的一个保护。 | 这个是为了避免别人直接使用你的识别库的一个保护。 | ||
这个密码是生成识别库的人员提供的。 | 这个密码是生成识别库的人员提供的。 | ||
| + | |||
探测步长 | 探测步长 | ||
| 第57行: | 第88行: | ||
当测试模式为0的时候,软件会一直处理下去,直到用户点击停止。 | 当测试模式为0的时候,软件会一直处理下去,直到用户点击停止。 | ||
这个模式是为了方便调试程序。 | 这个模式是为了方便调试程序。 | ||
| + | |||
| + | ==说明== | ||
| + | 帐号越多越好。越多帐号,单位时间里,每个帐号处理的编号就越少,从而导致帐号被封的几率就越低。 | ||
2016年9月3日 (六) 04:02的最新版本
简介
这是一个提取江苏工商新公司名称的工具。
功能
指定一个起始编号,依次检查后续编号的有效性。
获取有效编号对应的公司名称。
需要支持多个帐号轮换登陆。
需要识别图像验证码。
需要支持多个初始编号。
需要处理验证码识别失败的情况
需要处理登陆状态过期的情况
需要处理帐号禁用的情况。
使用
先安装软件
然后用您的用户和密码登陆软件,
然后把我们发给您的"辅助配置"压缩包里的文件解压到c:\output,
然后修改用户列表文件里的用户和帐号,
然后修改初始编号中的初始编号,
然后点击开始提取就可以了。
设置
工作目录=c:\output
探测步长=20
测试模式=0
工作目录
工作目录指定了软件的工作目录,
软件会从这个工作目录中读取相应的配置文件。
软件也会把输出结果写到这个工作目录。
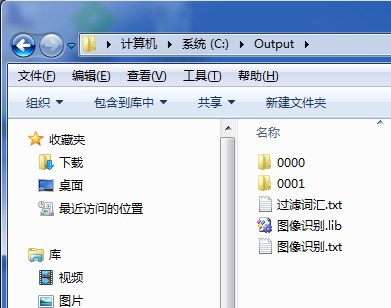
工作目录中的文件组织结构如下
过滤词汇.txt
图像识别.lib
图像识别.txt
子配置目录(例如0000 0001 0002)

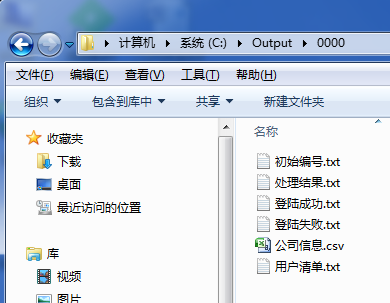
子配置目录中的关键文件如下
初始编号.txt
用户清单.txt

用户清单.txt
这是一个纯文本文件,
每行是一个用户信息,
一行内容的前面是用户名,后面是密码,中间是英文的逗号。
初始编号.txt
这也是一个文本文件。
文件里面就是初始编号。
软件在启动的时候会从这个文件读取初始编号,
在退出的时候,会把最后有效编号的下一个编号保存在这个文件里。
这样确保用户之需要设置一次,就可以反复运行。
图像识别.lib
帐号登录的时候,有验证码。
这个模块是验证码识别库。
使用识别库,只是构建识别库的时候付费一次,以后就可以不用另外付费,识别验证码了。
不象在线打码的识别机制,每次识别一个图片都要钱。
长期而言是非常合算的。
图像识别.txt
这个文件包含了图像识别库的密码。
这个是为了避免别人直接使用你的识别库的一个保护。
这个密码是生成识别库的人员提供的。
探测步长
这个参数指定了一个帐号探测多少个号码。
软件内部的探测逻辑如下:
假设初始值为1,探测步长为20,那么
第一次探测,1,2..20,发现有效编号是1,5,10,那么把有效编号的公司名字记录下来,然后把初始值调整为11
第二次探测,11,12...30,发现有效编号是14,17,18,那么把有效编号对应的公司名字记录下来,然后把初始值调整为19
.....
探测步长有两个用途:
一个是为了避免因为某个编号是无效编号,从而倒是软件反复检查这个编号;
一个是为了提升处理的效率,一次性的连续探测多个编号比每次只处理一个编号效率高。
测试模式
当测试模式为1的时候,处理使用一个帐号处理一组编号就会停止下来。
当测试模式为0的时候,软件会一直处理下去,直到用户点击停止。
这个模式是为了方便调试程序。
说明
帐号越多越好。越多帐号,单位时间里,每个帐号处理的编号就越少,从而导致帐号被封的几率就越低。