“中国门博网信息采集”的版本间的差异
来自JsRobot
(→数据) |
(→数据) |
||
| (未显示同一用户的3个中间版本) | |||
| 第13行: | 第13行: | ||
每个栏目进行分页处理,然后采集每个列表页里的内容。 | 每个栏目进行分页处理,然后采集每个列表页里的内容。 | ||
==演示== | ==演示== | ||
| − | [[image: | + | [[image:menbowangxinxicaiji.gif]] |
| + | |||
==数据== | ==数据== | ||
| − | 数据样例:[[Media: | + | 数据样例:[[Media:menbowangshuju.rar|menbowangshuju.rar]] |
==备注== | ==备注== | ||
该网站一共是21311条数据,但是每个账号最多只能采集20000条数据。 | 该网站一共是21311条数据,但是每个账号最多只能采集20000条数据。 | ||
最好一个栏目一个栏目地地采集。保证2个栏目的采集是全的。 | 最好一个栏目一个栏目地地采集。保证2个栏目的采集是全的。 | ||
| − | 因为涉及到登录,不能异地同时登录采集,需要一方退出后采集。 | + | 因为涉及到登录,不能异地同时登录采集,需要一方退出后采集。 |
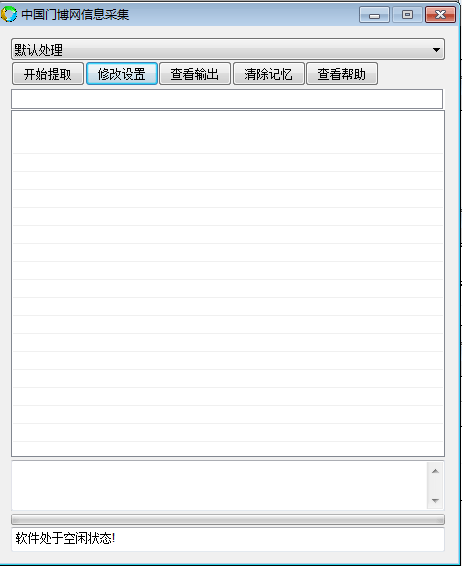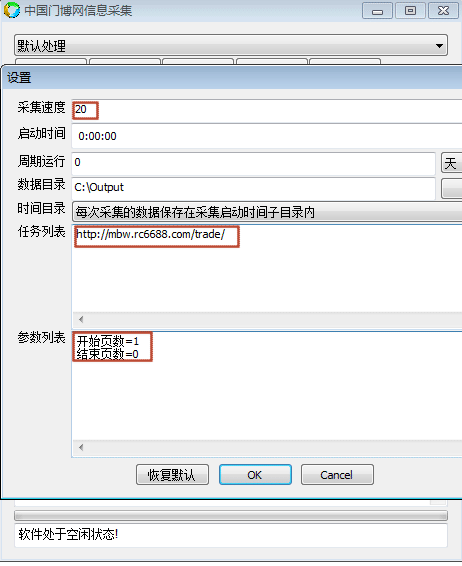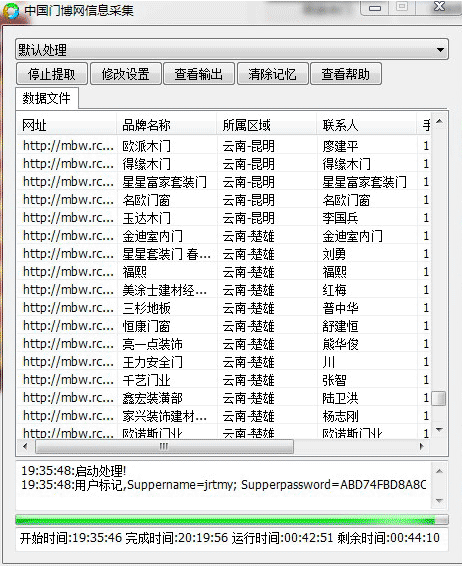
采集有两个开关:(方便从第几页到第几页采集,防止采集过快导致无法采集) | 采集有两个开关:(方便从第几页到第几页采集,防止采集过快导致无法采集) | ||
开始页数=1 | 开始页数=1 | ||
结束页数=0 | 结束页数=0 | ||
| + | 操作方法:点击提取数据,弹出一个浏览器,在浏览器里登录,然后再点击提取数据。 | ||
2016年9月20日 (二) 13:42的最新版本
简介
中国门博网信息采集。 客户要求采集相关信息,为此我们编写了一款软件自动化采集。
功能
采集目标 http://mbw.rc6688.com/trade/ 采集要求 批量采集列表页里的字段:联系人,电话 ,名字 分3个栏目: 百城万店 展会 其他渠道 每个栏目进行分页处理,然后采集每个列表页里的内容。
演示

数据
数据样例:menbowangshuju.rar
备注
该网站一共是21311条数据,但是每个账号最多只能采集20000条数据。 最好一个栏目一个栏目地地采集。保证2个栏目的采集是全的。 因为涉及到登录,不能异地同时登录采集,需要一方退出后采集。 采集有两个开关:(方便从第几页到第几页采集,防止采集过快导致无法采集) 开始页数=1 结束页数=0 操作方法:点击提取数据,弹出一个浏览器,在浏览器里登录,然后再点击提取数据。