“易撰网信息采集”的版本间的差异
来自JsRobot
(→功能) |
(→演示) |
||
| 第19行: | 第19行: | ||
先打开软件,然后选择“全部采集”,点击修改设置,可以设置 --提取参数,采集开始和结束页数。 | 先打开软件,然后选择“全部采集”,点击修改设置,可以设置 --提取参数,采集开始和结束页数。 | ||
==演示== | ==演示== | ||
| − | [[image: | + | [[image:yizhuanwang_canshu.gif]] |
| + | |||
==数据== | ==数据== | ||
数据样例:[[Media:oced_data.rar|oced_data.rar]] | 数据样例:[[Media:oced_data.rar|oced_data.rar]] | ||
2018年11月5日 (一) 18:11的版本
简介
易撰网的文章很多是畅销贴,点击量非常高,采集下来是非常有价值的。 为了方便的查看数据,我们写了一个提取数据的工具。
功能
采集目标 https://www.yizhuan5.com/ 采集要求 采集自媒体下百家号的文章 需要先登录网站,然后点击筛选,筛选点击量比较高的百家号的文章。 采集字段:网址,公众号,时间,标题,文件 样例网址: https://mbd.baidu.com/newspage/data/landingshare?context=%7B%22nid%22%3A%22news_9499981322380932157%22%2C%22sourceFrom%22%3A%22bjh%22%7D 按图片+TXT文章的格式下载,文件夹命名为文章的标题,文章.txt和下载的图片都保存在文件夹里,文章.txt里,需要把图片位置替换为 这里是文章图片\0.JPG,这里是文章图片\1.JPG等等。 输出数据
操作说明
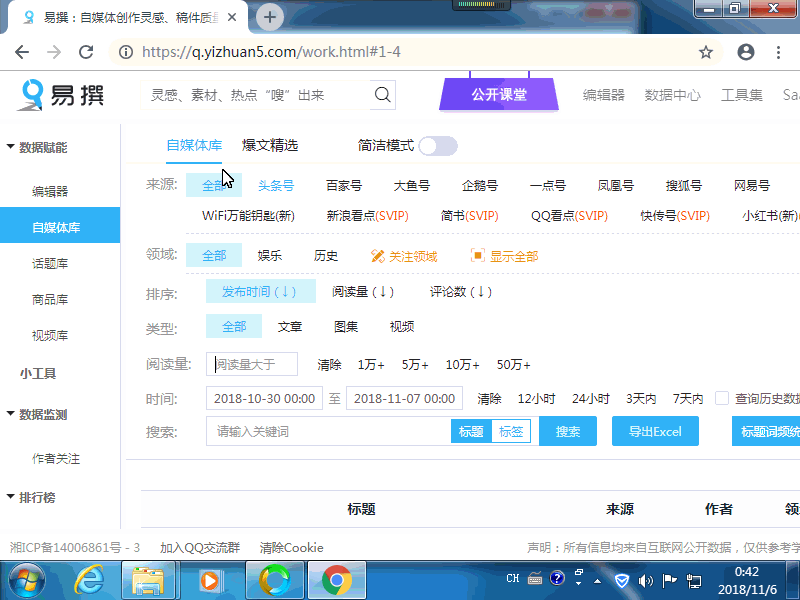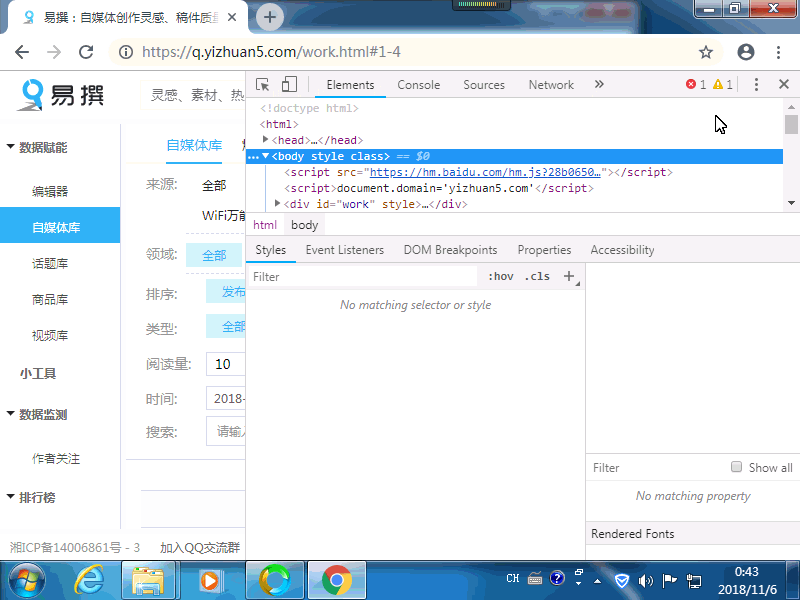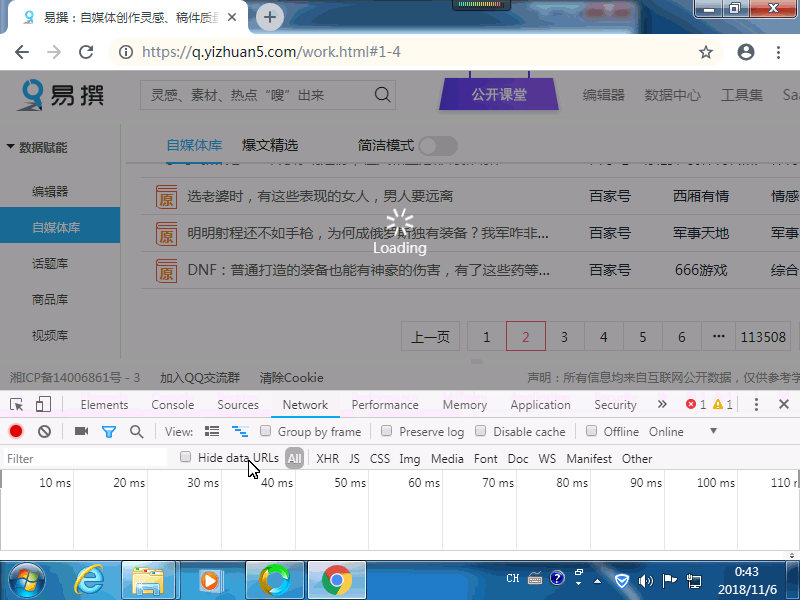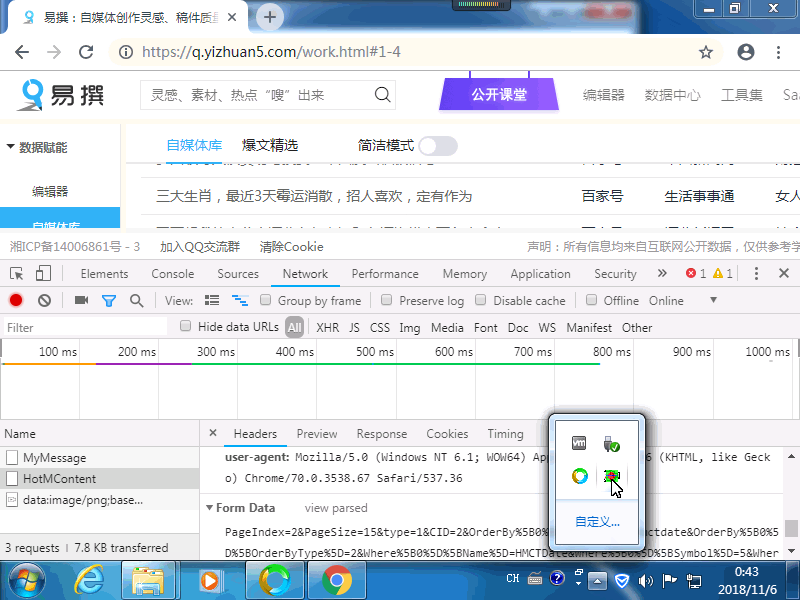
提取参数,先下载安装谷歌浏览器,然后打开网址登录,并设置好筛选条件,按F12,弹出开发工具,选择network,然后手动翻一页,再选择左边选择左边的HotMContent的最新数据包,选择Headers,选择From Data,选择view Parsed,然后按住鼠标左键,从左边拖到右边,ctrl+v复制,然后复制到软件里提取参数后面。 自动登录做好了。只需要设置好登录账户和密码,还有参数,就可以采集了。 先打开软件,然后选择“全部采集”,点击修改设置,可以设置 --提取参数,采集开始和结束页数。
演示

数据
数据样例:oced_data.rar
备注
采集有两个必要条件: 需要把“过滤百家号作者文件.txt”文件拷贝到C:\OUTPUT目录中,也可以新建一个文本重命名。然后里面的作者名一个一行保存。 需要在谷歌里访问要采集的网站,并把过滤条件都设置好,复制出参数粘贴到软件的提取参数后。