OpenLaw法律文书采集
来自JsRobot
摘要
这个工具解决OpenLaw的法律文书采集问题。
展示



背景
OpenLaw 开放法律联盟,2014年成立于上海。是一个面向律师、法官、检察官、法学教师、学者、学生以及从事法律相关的工作人员的 NGO 开放型组织,OpenLaw 的用户被视为法律技术和知识的源泉,共同分享法律专业知识以及智慧和经验成果。
OpenLaw是获取法律方面的资料的一个最有效的途径。
需求
字段列表
案由,标题,法院,类型,程序,案号,判决时间,审判长,审判员,书记员,原告,被告,上诉人,被上诉人,再申请人,被申请人,第三人,申诉人,被申诉人,赔偿请求人,义务机关,公诉机关,复议人,追加人,申请执行人,被执行人,原告委托人,原告代理人,原告律师,原告律师事务所,被告委托人,被告代理人,被告律师,被告律师事务所,涉及法律法规,判决内容
位置信息

特殊要求
涉及相关人物时,多个用‘,’因为逗号隔开,相关人物可能为公司
大数据问题
大量访问的时候,网站会提示验证码,会封IP。

显示的不完整
有些页面,只显示到100页,需要处理这个问题
采集难度很高
客户已经找了4个采集人员做,都没有做下来。
功能
输入
默认网址
输出
输出内容
案件信息
案件编号.htm
案件编号.txt
数据文件.csv
数据文件的字段列表如下
网址,编号,案由,标题,法院,类型,程序,案号,判决时间,审判长,审判员,书记员,原告,被告,罪犯,上诉人,被上诉人,再申请人,被申请人,第三人,申诉人,被申诉人,赔偿请求人,义务机关,公诉机关,复议人,追加人,申请执行人,被执行人,原告委托人,原告代理人,原告律师,原告律师事务所,被告委托人,被告代理人,被告律师,被告律师事务所,涉及法律法规
案件编号.htm
保存完整的网页内容
案件编号.txt
保存案件正文内容,去掉所有HTML字符
处理
枚举城市列表
枚举城市中的法庭列表
枚举一个法庭发出的文书
提取文书内容,解析字段并保存。
使用
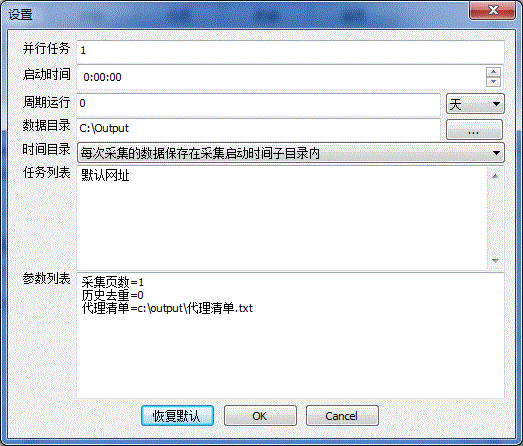 采集页数:一个法庭判决的案件有许多件。案件列表页都有许多页。这个参数指定采集多少页。默认设置为1页。
历史去重:是否以前已经采集过的就不予采集。默认为0。
代理清单: 默认设置设置为c:\output\代理清单.txt。该文件内容放代理服务器的信息,每行是一个代理服务器。每行内容是Ip:端口。
如果每天都采集,那么就可以把采集页数设置为1,历史去重设置为1。我们大致可以想象的出,一个法庭一天判决的案件不会特别多。采用这样的设置采集起来是最快的,也是很有效的。
如果一个月采集一次,那么就必须把采集页数设置为一个很大的值。这样就可以确保把所有的案件都采集下来。
采集页数:一个法庭判决的案件有许多件。案件列表页都有许多页。这个参数指定采集多少页。默认设置为1页。
历史去重:是否以前已经采集过的就不予采集。默认为0。
代理清单: 默认设置设置为c:\output\代理清单.txt。该文件内容放代理服务器的信息,每行是一个代理服务器。每行内容是Ip:端口。
如果每天都采集,那么就可以把采集页数设置为1,历史去重设置为1。我们大致可以想象的出,一个法庭一天判决的案件不会特别多。采用这样的设置采集起来是最快的,也是很有效的。
如果一个月采集一次,那么就必须把采集页数设置为一个很大的值。这样就可以确保把所有的案件都采集下来。

如果你只关注某个城市的法庭判决的案件,那么你也可以把任务列表中的内容,修改为某个特定城市的网址。
例如,你要采集“北京”的案件,那么就可以把任务列表中的内容修改为,http://openlaw.cn/justic/court.jsp?zone=%E5%8C%97%E4%BA%AC%E5%B8%82
如果你只关注某个法庭判决的案件,那么你也可以把任务列表中的内容,修改为某个法庭的网址。
例如,你要采集“北京市高级人民法院”的案件,那么就可以把任务列表中的内容修改为,http://openlaw.cn/court/ad0237a686644b33ac48b655a0f5271c
如果你只关注某个特定的案件,那么你可以把任务列表中的内容修改为某个特定案件的网址。
例如,http://openlaw.cn/judgement/c0bfd1189298493c9a57777dc53cfae0
说明
这个网站有几个反采集措施。
一个是网站加密的逻辑。这块采用了某些XSS注入的技术实现了代码加密。常规的访问无法获取内容。
一个是IP保护。如果一个IP访问的页面过多,就会弹出验证码。这个只能采用高匿的代理服务器绕过。
代理服务器必须使用高匿的代理服务器。你可以在网上百度“代理 自助”获得那些卖代理服务器的网站,然后在这些网站上就可以获取代理服务器的IP和端口信息。
代理自助网站提供的代理不一定都是可用的,必须使用工具验证一下,把无法使用的代理服务器剔除掉。
代理服务器的类型必须是高匿的。非高匿类型的代理服务器,都会被网站找到原始的IP。您在代理自助网站上到处代理信息的时候,必须注意这个问题。